Like this story...?

One of the problems faced by software developers when building data-driven web sites is the issue of displaying very long lists of data to the user. Anybody who has ever browsed the web will know about this - you search for something (eg. a product at an online retail store) but your search criteria are not specific enough to identify one, or even a small number, of products so you are told something like "3917 found" followed by a list of the first twenty products. There will usually also be buttons or hyperinks to see the next page of twenty items, or the first page, or the last page or even a specific page of your choice.
Sounds simple, right? It is certainly pretty logical and intuitive for the user. But up until relatively recently this simple problem could only be solved with some quite complex code behind the scenes. The data in modern databases is almost invariably accessed by a language called Structured Query Language, or "SQL" as it is widely (and often inaccurately) known. Most databases conform fairly closely to a standard set of SQL statements, so whether you are working with Microsoft SQL Server, IBM's DB2 or an Oracle database things are pretty similar.
The problem with SQL is that it was designed to deal with large amounts of data very quickly and not small contiguous subsets of the data (like the first twenty items, followed by the next twenty items and so on). To deal with this problem, developers had to write complex code that kept track of the first and last item in the current page of data, then submit a new SQL query each time the user clicked "next page" or "previous page" ; this SQL query would have to be modified each time to ensure that the twenty items AFTER the current last one were retrieved, or the twenty items BEFORE the current first one.
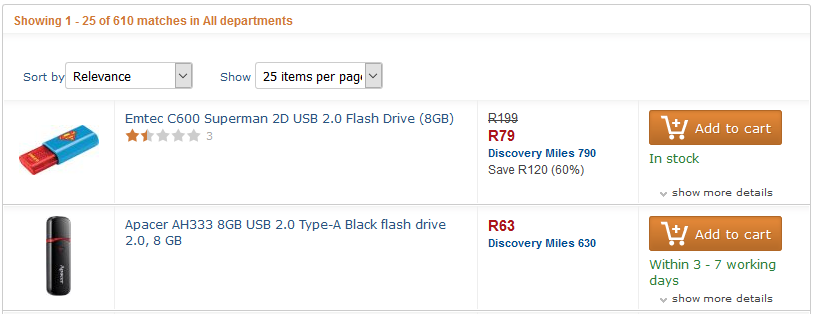
But some time ago this problem was solved by the addition of a clause into the standard SQL data retrieval statement that allowed the developer to specify the relative row number to START FROM within the larger set of data and also HOW MANY ROWS to return. This means that (for example), 3917 items may satisfy the search criteria provided by the user but the SQL data retrieval statement will only return rows 61 to 80 (page 4 if there are 20 rows per page), rather than all 3917 rows. The crucial part of this new clause is that both the starting row number (called the "offset") and the number of rows to return can be a variable, meaning that the same SQL statement can be used for all kinds of paging - the developer simply provides a new starting row number (offset) each time the user pages up or down. In this way scrolling through large sets of data becomes absurdly easy.
For those more technically minded, here is an example to illustrate what I'm talking about. Assume you have a Microsoft SQL Server database with a table called "Product" that has a column called "ProductName". Looking for and displaying a subset of all the products that contain the word "shirt" can be done as simply as follows:
select *
from Product
where ProductName like '%shirt%'
order by ProductName
offset @rowOffset rows
fetch next 20 rows only
The "@rowOffset" variable must be supplied by the system and indicates the starting row number. The complete solution in stored procedure form is:
create procedure ProductSearch
@rowOffset int,
@rowsPerPage int,
@searchFor varchar(255)
as
select *
from Product
where ProductName like '%' + @searchFor + '%'
order by ProductName
offset @rowOffset rows
fetch next @rowsPerPage rows only
You can immediately see how simple it is merely to keep track of the current top row number and add (for example) 20 to it then call the stored procedure when the user clicks "page down". Paging up or backwards means you would subtract 20 from the current top row number ; the first and last pages need some minor additional checking but this is trivial. There are many variations to the solution presented above, such as providing a page number rather than a row number, but they all do essentially the same thing.
So this simple little modification to the old SQL select statement has made a massive difference to the complexity of many web systems dealing with large databases that can be searched by the public. I have built solutions similar to the above several times and still shake my head at the amount of work that used to be involved in implementing this kind of paging ...
 © Paul Kilfoil, Cape Town, South Africa
© Paul Kilfoil, Cape Town, South Africa